Offshore Westerly as an External Reasoning System: Quantitative Analysis of a Thirteen-Year Assumption Ledger
Ian A. Maxwell
Abstract
This paper presents a longitudinal analysis of Offshore Westerly, a corpus of 5,647 posts published between April 2013 and July 2026, read here as an external reasoning system rather than a conventional blog. Human reasoning is normally invisible because memory preserves conclusions while discarding most of the intermediate models that produced them; external reasoning systems preserve those intermediate states, allowing reasoning itself, not only its conclusions, to become an empirical object. The corpus was retrieved directly from the WordPress publishing platform and annotated with a schema-constrained large language model that assigned a primary category, secondary categories, subject, tone, keywords and named entities to every post, from which aggregate statistics were derived at the post, month, and year level. Publication volume follows three phases: prolific from 2013 to 2016, sharply reduced from 2017 to 2022, and revived from 2023 onward, with thematic composition shifting from a Personal and Society mix in the founding years to a Society-led, increasingly AI-inflected mix in the revival, while Observational and Critical tones dominate throughout. Against this quantitative backbone, the paper argues that a small set of recurring modelling primitives, information, explicit assumptions, simplification, limiting cases, contradiction, incentives, measurement and falsifiability, recur across otherwise unrelated subjects and constitute a more stable feature of the archive than any single topic. The mechanism underlying this continuity, an assumption ledger, is set out explicitly and traced through two worked examples from different domains. Two closing qualitative sections consider recurring metaphysical commitments across the corpus and then ask, directly, whether a coherent and self-aware practical life philosophy emerges from more than thirteen years of writing. The principal contribution is methodological: a long-running personal reasoning archive can be analysed quantitatively through structured language model annotation while retaining sufficient semantic structure to investigate conceptual continuity across the archive.
1. Introduction
Human beings have long externalised thought. Laboratory notebooks preserve experimental observations, engineering notebooks record design iterations, and mathematicians retain failed proofs alongside successful ones. These artefacts preserve intermediate reasoning and reduce dependence on biological memory, which compresses experience into conclusions and discards much of the reasoning that produced them. Digital publishing platforms, designed for communication, incidentally provide a similar capability: a searchable, chronologically ordered record capable of preserving observations, hypotheses and models over many years.
Offshore Westerly emerged gradually into such a record. It did not begin as a research project. Its earliest purpose was personal: it began in part as an extended love letter to the author’s wife, a place to keep experiences and observations that might otherwise be forgotten. Over time, as entries accumulated, individual posts increasingly became components of a longer reasoning process: observations generated assumptions, assumptions suggested explanatory models, and models were tested against limiting cases and deliberate counterexamples. Contradictions were retained rather than deleted, because they marked assumptions that needed revision. The public nature of the archive mattered to this evolution, though not by supplying its primary audience. Even though its principal audience remained the author, the possibility that another reader might examine the reasoning encouraged a clearer separation between observation, assumption and conclusion than a private diary would have required: public accessibility did not make the archive a performance for others so much as it acted as a weak quality-control constraint on private reasoning.
This distinction matters for how the corpus should be read. Many entries are not statements of settled belief but intermediate reasoning; a strongly worded post is often a stress test applied to an assumption rather than advocacy for the conclusion stated. Unlike memory, which preferentially keeps conclusions and discards the reasoning that produced them, the archive deliberately keeps unsuccessful ideas and abandoned models, so that reasoning itself becomes observable across more than thirteen years rather than reconstructed after the fact.
This paper treats the 5,647 posts published between April 2013 and July 2026 as a longitudinal record of externalised reasoning, made newly tractable for quantitative analysis by large language model annotation. Six questions are addressed: how publication activity evolved over more than thirteen years; how the dominant subject domains changed; which tonal characteristics remained stable despite changing subject matter; which recurring entities and keywords reveal persistent areas of attention; to what extent the underlying reasoning process remained stable while the problems it was applied to changed; and, read qualitatively rather than statistically, what recurring metaphysical commitments the corpus expresses. The central argument is that the most significant continuity in the archive lies not in its topics, which changed considerably, but in its method of reasoning, which appears substantially more stable. Human reasoning is normally invisible because memory preserves conclusions while discarding most of the intermediate models that produced them; what follows treats Offshore Westerly as a case where that discarding did not happen, so that reasoning itself becomes an empirical object rather than something inferred only from its outputs.
2. Offshore Westerly as an External Reasoning System
Conventional blogs are communicative artefacts, judged by readership, engagement or influence. The present archive, while public throughout, functioned principally as a persistent external reasoning system in which publication was simply the storage mechanism. This distinction changes how individual posts should be read. A conventional essay typically represents a position its author presently holds; many entries in Offshore Westerly instead represent intermediate states in a longer reasoning process, later strengthened, modified, or abandoned.
The recurring operational cycle visible across much of the archive can be summarised as observation, in which an event, idea or inconsistency is identified; assumption, in which one or more explicit assumptions are proposed to explain it; model, in which those assumptions are assembled into an explanatory structure; limiting-case exploration, in which the model is pushed to a deliberately simplified or extreme condition to expose hidden implications; contradiction, in which an implausible or inconsistent consequence signals that an assumption needs revision; and revision, in which the model is updated while the reasoning that motivated the change is preserved rather than erased. This approach is familiar from mathematics and theoretical physics, where limiting cases and proof by contradiction are standard tools, and it recurs across the archive’s subjects as diverse as artificial intelligence, quantum computing, economics, politics, business strategy and personal relationships. Read this way, many apparently categorical statements in the corpus function as experimental conditions rather than declarations of belief; their purpose is to reveal what follows from an assumption pushed to its limit, not to assert that the limit itself is true.
A second distinguishing feature is the explicit preservation of rejected ideas. Ordinary memory compresses reasoning, discarding intermediate hypotheses once a satisfactory explanation is reached; this archive resists that compression, keeping failed models alongside successful ones because understanding why a model was abandoned is often as informative as understanding why another survived. Over more than thirteen years this becomes a form of assumption ledger, analogous to the audit trails, design histories and laboratory notebooks maintained in engineering, finance and science for the same reason: a result is difficult to interpret without the assumptions under which it was reached. Each assumption recorded in the archive remains available for later confirmation or revision, so that new evidence updates existing models rather than silently replacing them, and the corpus becomes a continuously evolving network of reasoning rather than a disconnected sequence of essays.
2.1 The assumption ledger as a modelling framework
The assumption ledger is not simply a metaphor for the archive’s persistence; it is the specific mechanism by which the reasoning cycle described above accumulates rather than repeats. Three properties distinguish it from an ordinary sequence of essays. First, each entry in the ledger is addressable: an assumption stated in one post can be located, referenced, and revised by a later post without restating the reasoning that first produced it, in the way a financial ledger entry can be adjusted by a later entry without rewriting the account’s history. Secondly, the ledger records failure as well as success; a model that collapses under a limiting case is not deleted but retained alongside the assumption that broke it, so the archive documents which assumptions have already been tested and found wanting. Thirdly, the ledger permits versioning: the same underlying question can appear multiple times across the archive at different levels of refinement, each version building on, rather than replacing, the reasoning captured in the version before it.
2.2 Worked examples
Vanishment Theory (15 May 2026) illustrates the assumption ledger operating end to end, and is unusual only in that it renders the process explicit within a single, formally stated post rather than across several. Box 1 traces the six stages of the reasoning cycle as they appear in that post.
| Stage |
Content |
| Observation |
Standard quantum mechanics requires strict unitarity, so that probability is exactly conserved and nothing is ever fully lost from a quantum system. |
| Assumption |
Unitarity might instead be a limiting case of a more general rule, rather than an exact law, if quantum states can exist in superposition with non-existence itself. |
| Model |
The strict condition that the evolution operator satisfies U-dagger U equal to exactly 1 is relaxed to a bounded inequality, 0 less than or equal to U-dagger U less than or equal to 1, allowing a small amplitude of a state to genuinely vanish rather than merely transform. |
| Limiting case |
If vanishment is taken seriously and pushed to its extreme, ordinary conservation laws would appear to be violated at a small but non-zero rate, an implication most physical theories treat as immediately fatal. |
| Contradiction |
Apparent violation of conservation is, within ordinary physics, a strong signal that an assumption should be abandoned rather than pursued further. |
| Revision |
Rather than discarding the model, a generalised conjugate operation is introduced specifically to restore conservation on average, so the theory keeps the assumption that motivated it while repairing the consequence that appeared to break it. |
Box 1. The assumption ledger applied to Vanishment Theory.
Two features of this example generalise to the rest of the corpus. The relaxation from equality to an inequality, 0 less than or equal to U-dagger U less than or equal to 1, is itself a ledger entry: a previously fixed constant is deliberately loosened and the consequence of loosening it is tracked rather than assumed away. The revision at the final stage does not erase the limiting case that produced the contradiction; the apparent conservation violation remains part of the theory’s stated content, addressed rather than deleted, exactly as the assumption ledger predicts for a model that survives contradiction through revision rather than abandonment.
Because Vanishment Theory is speculative physics, a reader might wonder whether the ledger structure is itself an artefact of that domain rather than a general feature of the corpus. Markov evil (21 March 2026) traces the same six stages in an entirely different, non-physical setting, an everyday game rather than a physical theory, shown in Box 2.
| Stage |
Content |
| Observation |
In a simple finite-state game such as a card or dice game, players ordinarily assume that shuffling or rolling randomises the outcome. |
| Assumption |
If whoever controls the shuffling has complete knowledge of the current state, apparent randomness may conceal a fully determined outcome. |
| Model |
The game is represented as a finite-state process in which the shuffler chooses which transition occurs at each step, rather than the transition being drawn at random. |
| Limiting case |
Taken to its extreme, a shuffler with complete knowledge and full control over transitions can indefinitely avoid the game’s terminal states, keeping it in a loop forever without any single move looking obviously wrong. |
| Contradiction |
This appears to contradict the ordinary assumption that a game with a finite state space and well-defined winning conditions must eventually end. |
| Revision |
The model is revised to make explicit that finiteness alone does not guarantee termination; termination additionally requires that transitions be either genuinely random or bounded by rules preventing indefinite avoidance of terminal states, an assumption the ordinary belief that the game must end had left unexamined. |
Box 2. The assumption ledger applied to Markov evil, a non-physical example.
The same six-stage structure recurs with no physical content at all: a game-theoretic assumption is relaxed, pushed to a limiting case, found to contradict an ordinary belief, and revised by making an implicit precondition explicit. Read alongside Box 1, this indicates that the ledger structure is a property of how the archive reasons rather than a feature specific to speculative physics.
On this reading, the object of study in this paper is not the blog but the reasoning system that produced it, and the quantitative statistics reported in section 5 are best read as measurements of changing domains of active reasoning rather than simple measures of changing personal interests.
3. Related Work
The analysis sits at the intersection of content analysis, computational text-as-data research, and the study of external cognition. Traditional content analysis reduces large bodies of text to a structured set of categories suitable for statistical analysis (Holsti, 1969; Krippendorff, 2018), typically applied to newspapers, speeches or organisational documents. The present work adopts the same coding-frame logic but applies it to the longitudinal output of a single reasoning archive rather than to institutional or media communication, so that the coding frame measures changes in the domains occupied by a reasoning process rather than changes in public discourse.
The text-as-data paradigm treats large document collections as measurable behavioural records (Grimmer and Stewart, 2013; Grimmer, Roberts and Stewart, 2022), and recent work shows that instruction-tuned language models can perform text annotation at accuracy comparable to, and sometimes exceeding, human crowd-workers (Gilardi, Alizadeh and Kubli, 2023; Ziems et al., 2024). The present methodology follows that approach, classifying every post into a fixed taxonomy rather than attempting unsupervised topic discovery, in order to keep annotations comparable across the entire corpus, which spans more than thirteen years. Throughout, the language model functions as an annotator, converting each document into structured semantic fields, and not as a source of interpretation; the interpretation offered in later sections is the author’s.
The archive is also read here through the lens of external cognition, the proposition that reasoning is not confined to biological memory but is routinely extended into notebooks, diagrams, software and other persistent artefacts that reduce working-memory demands and preserve intermediate reasoning (Clark and Chalmers, 1998). Laboratory notebooks provide the closest analogy: they rarely contain only successful experiments, because failed experiments and abandoned hypotheses remain scientifically informative in their own right. Viewed this way, Offshore Westerly resembles a continuously maintained notebook for conceptual rather than experimental work, and its emphasis on models that could in principle fail connects it to the falsifiability criterion long used to distinguish explanatory from unfalsifiable claims (Popper, 1959). Finally, the volume pattern reported in section 5.1, prolific, then dormant, then revived, is broadly consistent with documented lifecycle patterns in blog research, where sustained personal publishing is episodic rather than constant and individual blogs evolve in function over their lifespan (Kaye, 2007).
4. Data and Methods
4.1 Corpus
The corpus comprises 5,647 blog posts spanning April 2013 to July 2026, retrieved directly from the Offshore Westerly WordPress archive (https://offshorewesterly.com/) rather than through search engine indexing, so that the complete published archive was obtained irrespective of external indexing policies. Aggregate frequency tables were derived from the post-level classifications at the post, month, and year level. Because the complete available archive was analysed rather than a sample, the descriptive statistics reported below refer to the entire published corpus rather than an estimate.
4.2 Retrieval pipeline
Posts were retrieved with a purpose-built Python streaming pipeline (wordpress_gpt_categoriser_streaming.py) designed around completeness, recoverability, determinism and scalability. The pipeline queries the site through the WordPress.com REST API, with the self-hosted WordPress core REST API (wp-json/wp/v2/posts) as a fallback, paginating through all published posts of type post between a configurable start and end month. Each retrieved record is deduplicated on post identifier and on a canonicalised URL, HTML content is stripped of script, style, and form elements and reduced to normalised plain text with BeautifulSoup, and word count and estimated reading time (words divided by 225 per minute) are computed from the cleaned text. Results are checkpointed to disk after every post, so a run can be interrupted and resumed from the last completed record without reclassifying prior posts, and aggregates are rebuilt at a configurable interval as classification proceeds, rather than only once at the end.
4.3 Classification
Each cleaned post was classified through a schema-constrained structured output interface. The pipeline’s configured model identifier was gpt-5-mini. Classification used a Pydantic response model that requires exactly one primary category, up to three distinct secondary categories, a concise subject description, three to eight keywords, up to ten named entities, exactly one tone label, a one-sentence factual summary of no more than thirty words, and a confidence score bounded between 0 and 1. The primary category is drawn from a fixed sixteen-value taxonomy (AI, Quantum, Technology, Science, Business, Economics, Politics, Law, Society, History, Health, Travel, Sport, Personal, Humour and satire, Other) and tone from a fixed nine-value taxonomy (Analytical, Satirical, Observational, Speculative, Personal, Explanatory, Critical, Narrative, Mixed). The classification prompt instructs the model to categorise the underlying subject or argument rather than a named entity in isolation, to reserve Humour and satire as primary only when the satirical device is itself the subject, and to avoid inferring facts not present in the post. Any output falling outside the fixed taxonomies is coerced to a defined fallback value (Other for category, Mixed for tone) rather than discarded, and keyword and entity lists are deduplicated and capped at the stated limits. This preference for constrained rather than open-ended prompting follows the author’s own prior work on vocabulary- and schema-constrained prompting as a means of improving the accuracy, precision and clarity of LLM outputs (Maxwell, 2025a, 2025b), applied here to classification rather than to text generation. The pipeline’s configuration records this identifier, but a precise reproducibility record, the exact dated API model snapshot, prompt version, code version, and generation temperature, was not separately preserved at the time of classification; where a provider does not expose a stable, permanently addressable model snapshot, this is a limitation of reproducibility rather than of the classification itself, and is treated as such in section 12.
4.4 Interpretation of categories
The analysis distinguishes four semantic levels that should not be read interchangeably. Primary categories describe broad domains of investigation; a post categorised as AI is not necessarily expressing an opinion about AI, but is using AI as a domain in which assumptions and models are explored. Subjects describe the specific idea examined in an individual post. Keywords are model-assigned semantic descriptors rather than literal word counts, so a keyword can be assigned even when the corresponding word rarely appears verbatim. Named entities identify specific people, organisations, technologies or places explicitly discussed. Category frequencies therefore describe the changing allocation of the domains within which reasoning occurred rather than a direct measure of lexical content.
4.5 Limitations of the classification approach
Automated classification of short or ambiguous posts carries inherent uncertainty, and a non-trivial share of the archive consists of posts with no substantive body content, discussed further in section 12. Because a single model performs all coding, the analysis cannot report inter-coder reliability in the conventional sense of agreement between independent human coders; confidence scores provide a per-post indication of the model’s own certainty but are not a substitute for inter-rater reliability statistics such as Cohen’s kappa or Krippendorff’s alpha. A single dominant primary category is also a simplification: many posts legitimately span multiple domains, an approximation only partly offset by the secondary category, subject, keyword and entity fields. This limitation is consistent with recent evidence that LLM annotation, while often accurate, is sensitive to implementation choices such as model and prompt selection, can introduce systematic rather than merely random error into downstream analysis (Baumann et al., 2025), and performs more reliably as an assistant to human coders than as a fully independent annotator (Gu et al., 2025; Calderon, Reichart and Dror, 2025).
4.6 A supplementary annotation-consistency check
This check was performed after the full corpus had already been classified in the pipeline described in sections 4.2 and 4.3, so it could not have influenced the original annotations; excluding shorter posts from this check does not affect the quantitative statistics reported in section 5, which are drawn from all 5,647 posts. To probe classifier behaviour beyond an unverified assumption of accuracy, fifty posts were drawn at random from the 3,811 posts in the corpus with at least thirty words of body content, using Python’s random.Random(42) for reproducibility. The remaining 1,836 posts fall below this threshold; based on the keyword patterns discussed in section 12, most are empty, title-only, or brief link or image posts rather than short but substantive entries, so the thirty-word cutoff was chosen to exclude posts too short to meaningfully check a category or tone assignment against. An earlier version of this check gave a second model only the title, subject, and summary produced by the original pipeline, and was found to measure consistency between two model-mediated representations rather than independent agreement, an information-leakage problem that is likely to inflate agreement. The check reported below corrects this: the full body text of each sampled post was retrieved directly from the live site, and a second large language model (Claude Sonnet 5), distinct from the gpt-5-mini classifier used for the full corpus, received only the post’s title and this freshly retrieved full text, withheld entirely from the original pipeline’s category, tone, subject, summary, keyword and entity fields. It was asked to assign a primary category and tone from the same two fixed taxonomies used throughout this paper, and its assignments were compared against the original labels.
Primary category agreement was 39 out of 50 posts (78 percent); tone agreement was 21 out of 50 (42 percent). Both figures are materially lower than the 96 percent and 94 percent respectively reported by the earlier, leakage-affected version of this check, consistent with the concern that reusing model-generated summary fields had inflated apparent agreement. Category disagreements cluster rather than scatter: 6 of the 11 disagreements involve the second model assigning Humour and satire as primary category where the original classifier had assigned Technology, Politics, Society, Business, or Personal, for posts such as Invention of the day, Careers, Solar energy, Extinction, Chook, and New Word for the Day, indicating that the two models draw the line described in the taxonomy’s own instruction, that Humour and satire should be primary only when the joke or satirical device is itself the subject, in different places despite working from the same written rule.
Tone agreement is markedly weaker than category agreement, and the pattern of disagreement is systematic rather than scattered. The second model assigned Satirical to 18 of the 50 posts against 2 in the original labels, and Personal to 11 against 6, while assigning Critical to only 6 against 20 in the original labels and Observational to only 5 against 13. The single largest confusion, Critical read by the original classifier and Satirical read by the second model, accounts for 8 of the 29 tone disagreements on its own, for posts including Auto Gourmet, Bring Back Tony, Marx and Orwell, Oxford, and Poll. This indicates that the two models apply materially different thresholds for reading dry, deadpan critical commentary as satirical irony, a genuine calibration difference between models rather than noise, and that tone in this taxonomy is a considerably softer, less reliably assigned label than primary category at this sample size.
This exercise is a useful signal rather than a validated reliability statistic: it drew on a sample of fifty rather than a pre-registered validation set, and it compares two language models rather than a language model against independent human coders, so it cannot substitute for the human validation study recommended in section 12. Within those limits, it supports two conclusions. First, the earlier leakage-affected check materially overstated agreement, particularly for tone, confirming that reusing pipeline-generated intermediate fields is not a safe substitute for checking against source text. Second, primary category assignments in Table 2 and Table 3 appear considerably more robust to which model performs the classification than tone assignments in Table 4 and Figure 4 do; the tone-based interpretive claims in section 5.3 and elsewhere in this paper should be read with that asymmetry in mind.
5. Quantitative Results
5.1 Publication activity
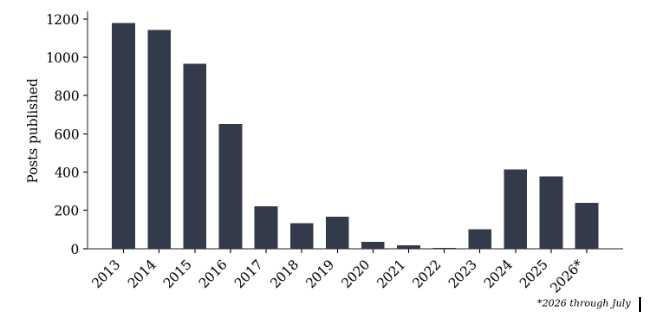
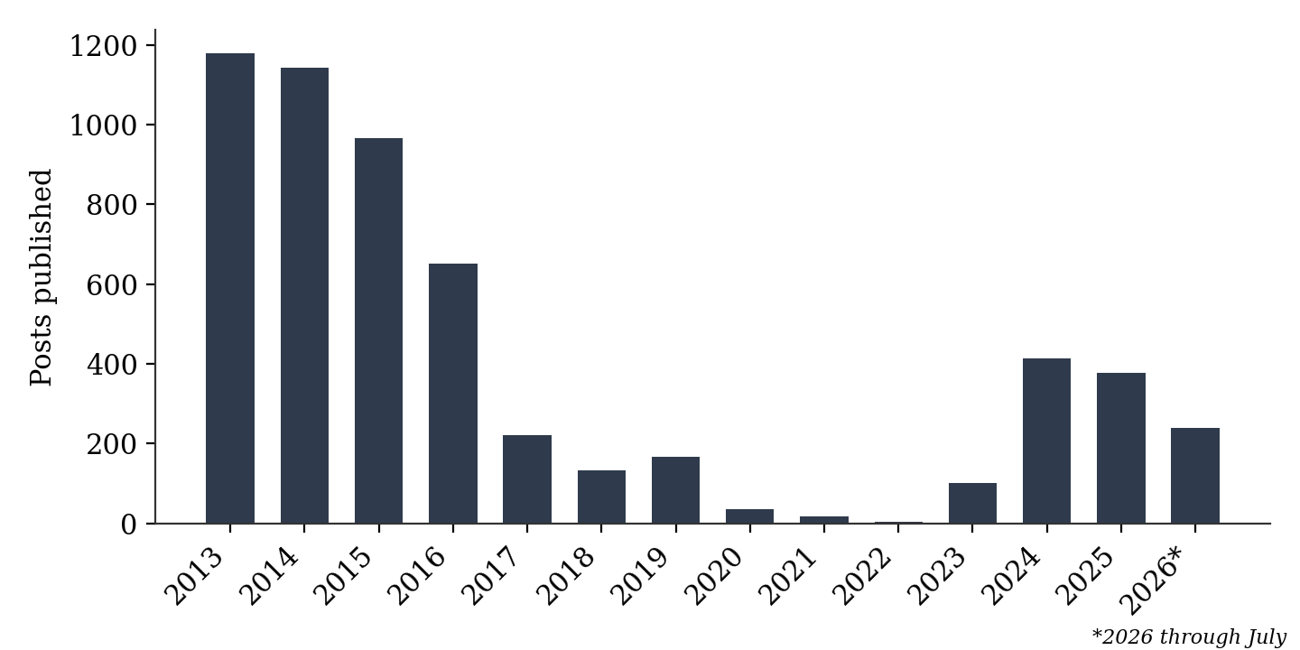
Table 1 and Figure 1 report the number of posts published in each calendar year. Publication volume follows three phases. Between 2013 and 2016 the archive was highly prolific, averaging over 900 posts a year and peaking at 1,179 posts in 2013, a period in which externalising reasoning through the archive appears to have been part of the author’s routine practice. The 2013 total covers April to December only, and the 2026 total covers January to July only; annual figures for those two years are therefore not directly comparable with the complete calendar years between them, and the 2013 peak in particular should be read as a high rate sustained over nine months rather than a full-year maximum. Between 2017 and 2022 output declined steeply, falling to a low of four posts in 2022; this decline should not be read as evidence that reasoning itself stopped, only that its externalisation through this particular archive became less frequent. From 2023 the archive resumed active publication, reaching 413 posts in 2024, the highest annual total since 2016, a revival that coincides with increasing attention to artificial intelligence and quantum computing.
| Year |
Posts |
| 2013 |
1,179 |
| 2014 |
1,142 |
| 2015 |
967 |
| 2016 |
652 |
| 2017 |
222 |
| 2018 |
132 |
| 2019 |
166 |
| 2020 |
35 |
| 2021 |
17 |
| 2022 |
4 |
| 2023 |
101 |
| 2024 |
413 |
| 2025 |
378 |
| 2026 (through July) |
239 |
Table 1. Posts published per calendar year, 2013 to 2026. 2013 (April to December) and 2026 (January to July) are partial years.
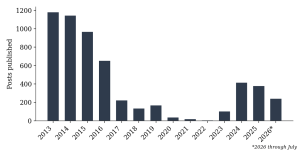
Figure 1. Posts published per calendar year, 2013 to 2026. 2013 covers April to December and 2026 covers January to July; these two totals are not directly comparable with the complete years between them.
5.2 Thematic composition
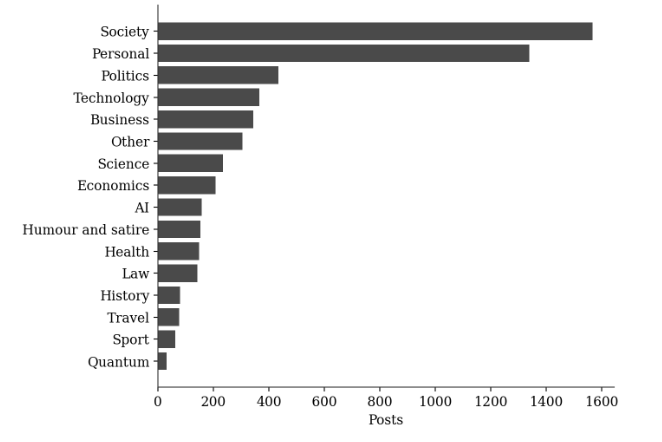
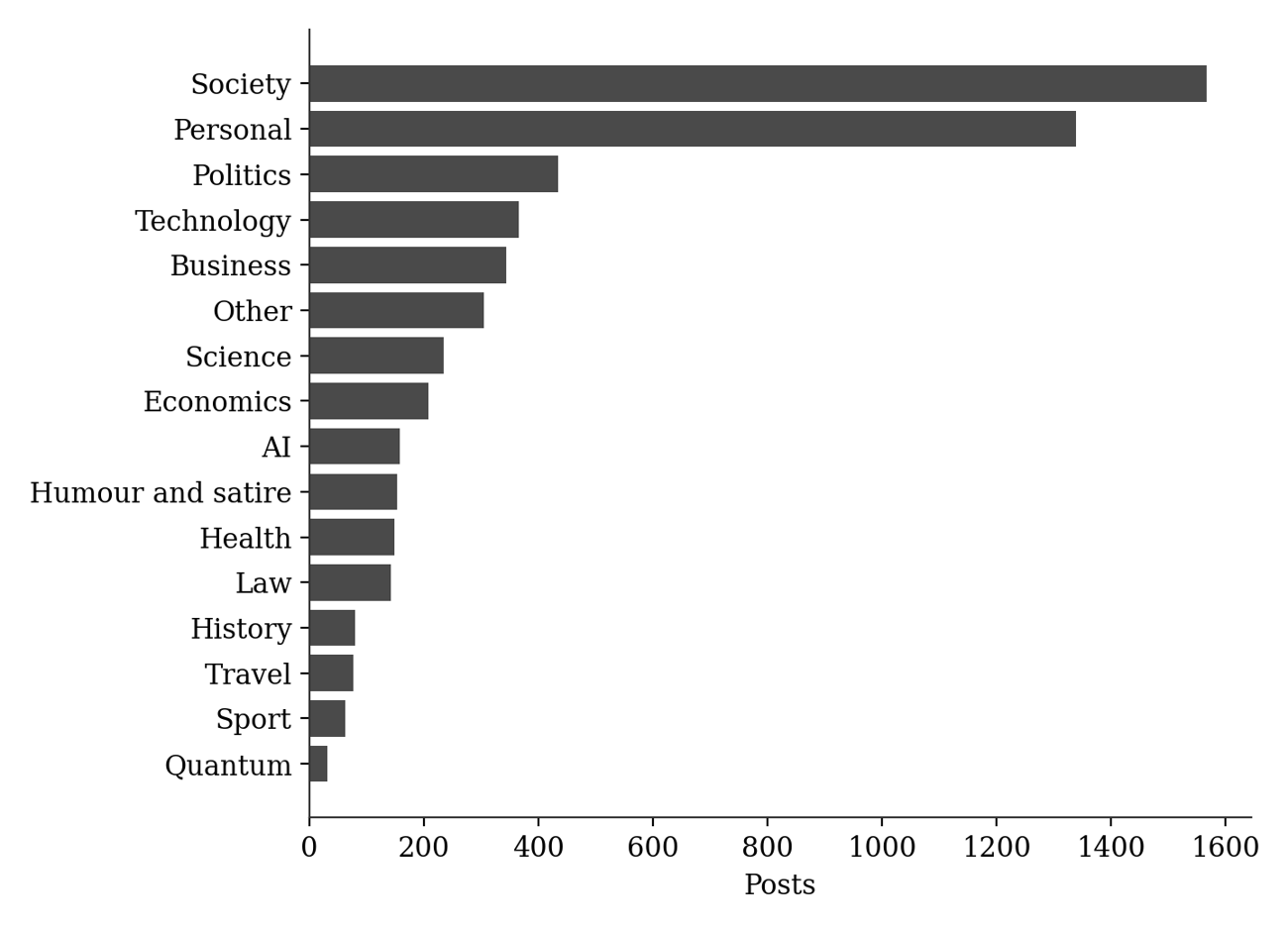
Table 2 and Figure 2 report the distribution of the sixteen primary categories across the full corpus. Society (27.8 percent) and Personal (23.7 percent) together account for just over half of all posts. Politics, Technology, and Business form a second tier, each between 6 and 8 percent. The remaining categories, including Science, Economics, Artificial Intelligence, Humour and satire, Health, Law, History, Travel, Sport, and Quantum, each account for less than 5 percent of the corpus individually.
| Category |
Posts |
Share of corpus |
| Society |
1,567 |
27.8% |
| Personal |
1,339 |
23.7% |
| Politics |
434 |
7.7% |
| Technology |
365 |
6.5% |
| Business |
344 |
6.1% |
| Other |
304 |
5.4% |
| Science |
234 |
4.1% |
| Economics |
208 |
3.7% |
| AI |
158 |
2.8% |
| Humour and satire |
153 |
2.7% |
| Health |
149 |
2.6% |
| Law |
142 |
2.5% |
| History |
80 |
1.4% |
| Travel |
76 |
1.4% |
| Sport |
63 |
1.1% |
| Quantum |
31 |
0.6% |
Table 2. Primary category distribution across the full corpus (n = 5,647).
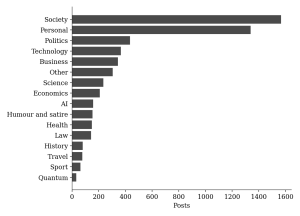
Figure 2. Primary category distribution across the full corpus.
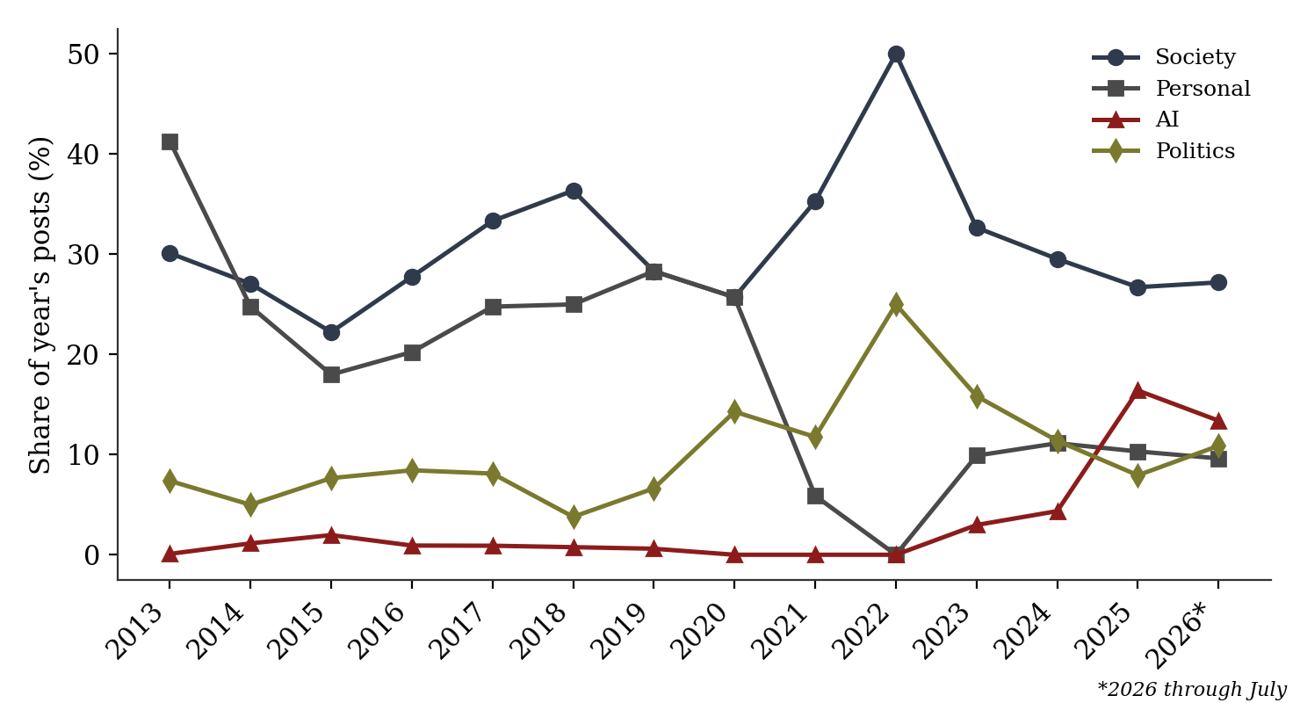
At first inspection this distribution resembles a typical personal blog combining commentary with autobiographical material. Read as a reasoning system, the categories instead identify the domains within which modelling occurred: a post categorised as AI is treated here as using artificial intelligence as an environment for exploring assumptions, prediction, and uncertainty, not necessarily as expressing a settled opinion about AI itself. Table 3 compares the leading categories in the founding year (2013) against the three most recent years. Personal content, the largest single category in 2013, falls out of the top three by 2025 and 2026, while Society remains dominant throughout, and Artificial Intelligence, absent from the leading categories in 2013, ranks second in both 2025 and 2026. Figure 3 tracks this shift across every year of the archive as a share of each year’s output.
| Year |
Total posts |
Leading categories (posts) |
| 2013 |
1,179 |
Personal 487, Society 355, Politics 87, Business 43, Technology 35 |
| 2024 |
413 |
Society 122, Politics 47, Personal 46, Science 26, Technology 22 |
| 2025 |
378 |
Society 101, AI 62, Personal 39, Science 33, Politics 30 |
| 2026 (through July) |
239 |
Society 65, AI 32, Politics 26, Personal 23, Technology 16 |
Table 3. Leading categories by post count, founding year versus recent years.
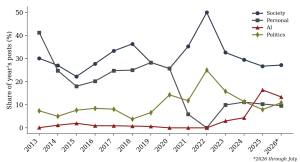
Figure 3. Share of Society, Personal, AI, and Politics categories by year, 2013 to 2026.
Across the quiet middle years, 2017 to 2022, Society and Personal remain the two largest categories in every year for which posts exist, with Politics, Business, Science and Economics present in small numbers throughout; the archive does not, in this period, pivot toward any single new technical domain, and the eventual rise of AI is a feature specifically of the 2023 to 2026 revival rather than a gradual trend across the quiet years.
5.3 Tonal register
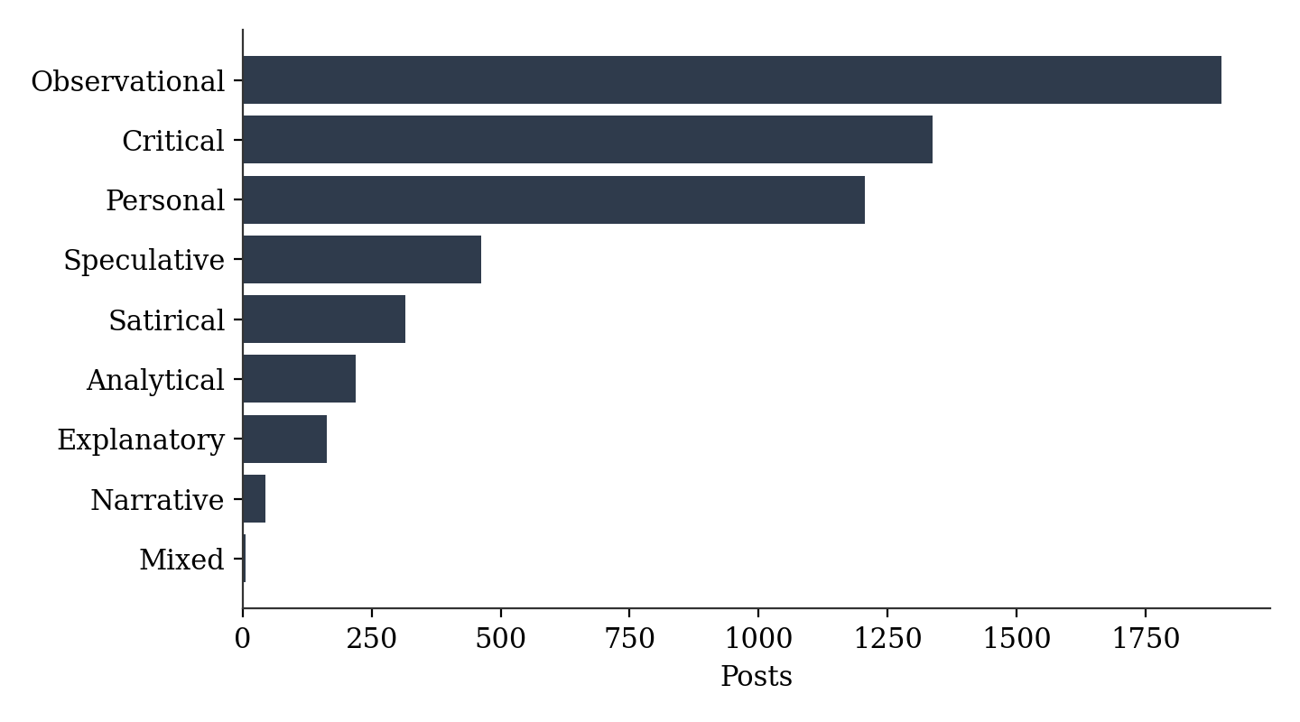
Table 4 and Figure 4 report the distribution of the nine tonal categories. Observational tone predominates at 33.6 percent of the corpus, followed by Critical (23.7 percent) and Personal (21.4 percent); together these three registers account for 78.7 percent of all posts. Speculative and Satirical tones each exceed 5 percent, while Analytical, Explanatory, Narrative, and Mixed registers each account for less than 4 percent.
| Tone |
Posts |
Share of corpus |
| Observational |
1,897 |
33.6% |
| Critical |
1,337 |
23.7% |
| Personal |
1,206 |
21.4% |
| Speculative |
463 |
8.2% |
| Satirical |
315 |
5.6% |
| Analytical |
218 |
3.9% |
| Explanatory |
163 |
2.9% |
| Narrative |
43 |
0.8% |
| Mixed |
5 |
0.1% |
Table 4. Tonal register distribution across the full corpus.
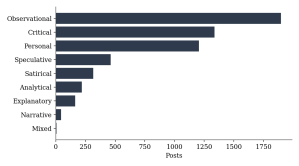
Figure 4. Tonal register distribution across the full corpus.
Read against the reasoning-system framework, this distribution is consistent with a corpus oriented toward explanation and inconsistency-checking rather than storytelling: this pattern is consistent with Observational entries often serving as inputs for later reasoning, Critical entries flagging inconsistencies for further work, and Analytical entries developing explanations directly, while purely Narrative writing remains a small fraction throughout. Tone labels describe register rather than function, so these functional readings are offered as a plausible interpretation of the distribution rather than something the tone label itself establishes; section 4.6 reports a supplementary check finding tone agreement between two models to be considerably lower than category agreement, so the tone-based statistics in this section should be read as the softer of the paper’s two main classification outputs. Satirical and humorous posts recur throughout the archive at a modest but consistent rate; several of the posts identified in section 7 use exaggeration specifically to expose a hidden assumption or contradiction, suggesting that humour functions here partly as a reasoning technique rather than only as entertainment.
5.4 Recurring entities and keywords
Table 5 reports the twenty most frequently occurring named entities. Australia was assigned as an entity to 379 posts, more than double the next most frequent entity, China (129 posts), followed by Sydney (110 posts). Two personal names, Lola and Viv, rank fourth and seventh respectively, ahead of most corporate and political entities, indicating a persistent personal dimension to the writing alongside its public affairs content. Google, GPT, Facebook, Uber, LinkedIn and ChatGPT also appear among the twenty most frequent entities, consistent with the archive’s recurring use of specific technology platforms as modelling environments rather than merely objects of commentary.
| Entity |
Posts assigned entity |
| Australia |
379 |
| China |
129 |
| Sydney |
110 |
| Lola |
92 |
| Google |
76 |
| United States |
61 |
| Viv |
46 |
| GPT |
43 |
| Facebook |
42 |
| Uber |
40 |
| LinkedIn |
37 |
| The Guardian |
34 |
| Queensland |
25 |
| Melbourne |
25 |
| Qantas |
23 |
| US |
23 |
| Tony Abbott |
23 |
| Australians |
22 |
| NSW |
21 |
| ChatGPT |
20 |
Table 5. Twenty most frequent named entities across the corpus. Counts are posts to which the model assigned each label, not normalised entity mentions; see section 12 on label normalisation.
Table 6 reports keyword frequency after excluding keywords that denote an absence of content (empty post, title-only, no content, missing content, and equivalent variants), which collectively tag several hundred posts. Among substantive keywords, Australia, anecdote, satire, and humor recur most frequently, followed by a cluster of terms related to parenting, social media, introspection, and relationships, consistent with the personal dimension identified above.
| Keyword |
Posts assigned |
| Australia |
173 |
| anecdote |
158 |
| satire |
143 |
| humor |
121 |
| parenting |
94 |
| social media |
90 |
| introspection |
88 |
| relationships |
82 |
| personal reflection |
79 |
| China |
71 |
| metaphor |
71 |
| language |
62 |
| identity |
62 |
| wordplay |
60 |
| skepticism |
58 |
| communication |
58 |
| automation |
53 |
| marketing |
52 |
| authenticity |
52 |
| empathy |
52 |
Table 6. Twenty most frequent substantive keywords, empty and title-only tags excluded. Counts are posts assigned each keyword by the model, not deduplicated concept frequencies.
6. Evolution of the Reasoning Process
The statistics in section 5 describe how publication activity and subject matter changed. They do not, by themselves, explain what changed. A conventional reading would conclude that the author’s interests moved from personal matters toward technology and public affairs. Read as an external reasoning system, the same statistics admit a different account: the dominant questions changed, while the reasoning process applied to them appears comparatively stable.
6.1 Phase I: externalising immediate experience (2013 to 2016)
The founding years are characterised by sustained, high-volume publication centred on Personal and Society, with Politics, Business, and Technology present as smaller secondary domains (Table 3). Personal entries frequently use individual experience as material for a broader model rather than as autobiography for its own sake, and Society provides the wider context in which personal and commercial observations are interpreted. The reasoning in this period is predominantly inductive: many entries begin with a concrete event before generalising toward a broader principle, a habit of abstraction that persists throughout the archive’s later evolution.
6.2 Phase II: reduced externalisation (2017 to 2022)
Publication frequency declines substantially in the middle years of the corpus (Table 1). Reduced publication need not imply reduced reasoning, only reduced externalisation of it through this particular archive; the present analysis cannot distinguish between reduced writing time, alternative recording mechanisms, or reduced need to think through problems in public. What is clear from Table 3 and the accompanying year-by-year category data is that Society and Personal remain the two largest domains throughout this period, with no single new domain coming to dominate the quiet years; the technical domains that come to prominence later, principally AI, are essentially absent here and emerge specifically with the 2023 to 2026 revival rather than gradually across the decline.
6.3 Phase III: artificial intelligence as a modelling domain (2023 to 2026)
The final phase is the most significant change in the corpus: Artificial Intelligence rises from absent among the leading categories in 2013 to second only to Society in both 2025 and 2026 (Table 3, Figure 3). Read only as a change of subject, this looks like an interest shift toward a fashionable technology. Read as a reasoning system, AI instead becomes a new and unusually productive environment for the same recurring questions the archive has long applied elsewhere: what constitutes understanding, what distinguishes prediction from explanation, how uncertainty should be represented, and how competing explanatory models should be evaluated. Quantum computing, present in smaller numbers throughout the later archive (31 posts, 0.6 percent of the corpus overall), plays a related but narrower role, treated consistently as a problem in information processing and computational limits rather than as a subject of purely technological enthusiasm.
6.4 Continuity beneath changing subjects
Viewed independently of chronology, a post on patent valuation, a post on quantum error correction, and a post on football administration read, in this corpus, as instances of the same underlying procedure: an observation is made, explanatory assumptions are proposed, a simplified model is built, the model’s consequences are examined, contradiction is actively sought, and the post concludes either by revising the model or by naming the remaining uncertainty. This architecture, examined further in section 7, is one for which the evidence is consistent with it being considerably more stable across the archive’s history than any of the subject categories reported in section 5.
7. Persistent Modelling Primitives
The categories, tones, entities and keywords reported in section 5 describe what the archive discusses. This section considers how the reasoning proceeds, through a small set of recurring conceptual operations referred to here as modelling primitives. Unlike a topic, a modelling primitive identifies a habit of construction that recurs regardless of subject matter, in roughly the way grammar recurs across changing vocabulary. The primitives below are illustrated with posts identified in the classified corpus rather than asserted only in the abstract.
7.1 Information
The archive repeatedly reformulates problems across business, artificial intelligence, quantum computing, and interpersonal relationships as problems of the acquisition, transmission, or interpretation of information. Time and information (30 June 2024) states this explicitly, proposing that the total knowable information is constant and exists outside time and distinguishing discovery from invention on that basis. Genes (11 April 2026) applies the same informational framing to the genome, treating it as a substrate for reservoir computing that generates complexity rather than storing it.
7.2 Explicit assumptions
Many entries begin by naming the assumptions under which a conclusion would follow, rather than asserting the conclusion directly. Vanishment Theory (15 May 2026), traced stage by stage against the assumption ledger in Box 1, is an example rendered as formal physics: rather than asserting that conservation laws are violated, it identifies the specific relaxation of unitarity, bounding it between 0 and 1 rather than requiring exact unity, under which small apparent violations would be expected, and proposes a generalised conjugate to restore conservation. The conclusion is conditional on the assumption remaining explicit and inspectable, which is precisely what the ledger structure is designed to preserve.
7.3 Simplification
Complex systems are repeatedly reduced to a small number of interacting variables before further complexity is admitted. Quantum Computing, explained (18 August 2025) reduces qubits, superposition, entanglement and decoherence to a single social metaphor in order to expose the dominant mechanism before any technical elaboration is introduced.
7.4 Limiting cases
Rather than examining the average case, many posts ask what follows if an assumption is taken to its extreme. Court (1 November 2024) asks what follows if a legal dispute is treated as formally analogous to quantum superposition, using Schrödinger’s cat to argue that settlements and verdicts collapse legal uncertainty in different, non-ground-truth ways. Markov evil (21 March 2026) pushes a simplified finite-state game to the limiting case of a shuffler with complete state knowledge, showing that such a shuffler can enforce deterministic outcomes indefinitely.
7.5 Contradiction
Contradictions are treated as informative rather than as failures to be smoothed over. Weird (4 February 2026) is the clearest example: rather than accommodating claims that quantum physics demonstrates consciousness preceding the material universe, the post treats the claim’s unfalsifiability as a defect serious enough to reject the claim outright, rather than reason to weaken the underlying standard of evidence.
7.6 Incentives
Institutional and personal behaviour is repeatedly explained through incentive structures rather than stated intentions, a pattern visible across the Business, Economics, Politics and Law categories in Table 2 and consistent with the archive’s broader preference for mechanism over description. Principal Agent (28 June 2016) makes the structure explicit, arguing that politicians should apply equal-percentage budget cuts across departments specifically to remove the discretion that enables clientelism, treating an institutional design choice as an incentive problem rather than a matter of individual virtue. TT (13 February 2019) applies the same logic to personal conduct, framing a choice of generosity over revenge as a way of breaking a cycle of workplace vindictiveness, an explicit reweighting of incentives rather than an appeal to niceness for its own sake.
7.7 Measurement
The archive repeatedly asks whether an observed quantity actually measures the phenomenon it is taken to represent, a scepticism reflected in the Critical tone’s 23.7 percent share of the corpus (Table 4). Stats Explained (16 November 2016) criticises the use of simple correlation, illustrated with a patent-distance example, as a stand-in for a causal claim it does not establish, a direct statement of the measurement primitive applied to research practice. The Easterlin Paradox (6 March 2025) applies the same scepticism to economics, questioning whether income is an adequate proxy for the well-being it is conventionally used to measure.
7.8 Falsifiability
Explanatory value is repeatedly associated with the possibility of failure rather than the capacity to accommodate any observation. Weird (section 7.5) again exemplifies this directly, and the same standard recurs in the corpus’s treatment of speculative physics, where Vanishment Theory is presented as a specific, bounded modification capable of producing a measurable prediction, tiny apparent conservation violations, rather than as an unconstrained metaphysical claim.
7.9 Stability across domains
Business gives way to artificial intelligence across the more than thirteen years (Table 3), and quantum computing appears where it had previously been absent, yet the same eight primitives can be identified organising individual posts throughout. The continuity in subject matter, measured directly in Table 2 and Table 3, is weak. The continuity in reasoning architecture is not measured in the same direct sense; it is an interpretation supported by the repeated presence of these primitives across otherwise unrelated posts, and the evidence is consistent with this second, more tentative form of continuity being considerably stronger than the first. It is this interpretation, not a directly measured quantity, that motivates reading Offshore Westerly as a reasoning system rather than as a themed sequence of essays.
8. Metaphysical and Philosophical Commentary
The modelling primitives in section 7 describe a recurring architecture of reasoning. This section sets that architecture aside and reads the same corpus for its recurring metaphysical commitments, illustrated with representative posts rather than aggregate counts.
From this point the paper shifts registers. Sections 5 and 7 report counts and recurring structures that another coder could in principle check against the same corpus. Sections 8 and 9 instead offer an interpretive reading of the same posts, closer to literary or biographical criticism than to content analysis, and the observations that follow are correspondingly more subjective. They should be understood as one plausible synthesis of recurring themes rather than as a statistically demonstrable finding, and a different reader working from the same corpus could reasonably draw a different synthesis.
8.1 Quantum formalism as a metaphor for non-physical domains
A persistent habit across the corpus is the use of quantum-mechanical concepts, principally superposition, entanglement, and collapse, as a vocabulary for phenomena with no physical quantum character at all. Posts including Love (20 November 2025), Entanglement (19 November 2025), Court (1 November 2024), Hilbertese (22 November 2025), and Schrödinger’s pussy (6 March 2014) each apply quantum formalism to romantic relationships, legal disputes, cognition, and perception respectively. The recurrence of this move over more than a decade suggests it functions as a standing conceptual tool rather than an isolated flourish, a way of making indeterminacy and observer-dependence in ordinary life legible through a borrowed physical vocabulary.
8.2 Nothingness and vanishment as a recurring motif
A second thread treats nothingness and vanishing as objects of sustained interest rather than mere negation. Vanishment Theory (15 May 2026) proposes, in the register of speculative physics, that quantum states may exist in superposition with non-existence itself, a formal literalisation of a motif recurring informally throughout the archive: Re-imagining Imagination (6 June 2016) questions the coherence of applying expansion to the infinite and muses on the limits of describing nothingness in language; No bang hypothesis (19 May 2024) speculates that energy and nothingness are mutually convertible through time; Death, the black hole and nothing (15 March 2016) and Butterflies (13 January 2016) each treat existential nothingness, the latter arguing that addictions are attachments best resolved by accepting nothingness on the far side of them. Vanishment functions as something close to a personal ontological signature, appearing for a decade in essayistic form before receiving explicit theoretical treatment.
8.3 A naturalistic and falsifiability-oriented stance on consciousness
Despite its taste for speculative and analogical physics, the corpus is consistently unsympathetic to non-naturalistic claims about mind. Weird (4 February 2026) rejects claims that quantum physics demonstrates consciousness existing before the material universe as unfalsifiable, alongside a series of posts treating consciousness as evolved and often discontinuous rather than fundamental: Consciousness (28 July 2015) proposes a social and evolutionary origin for self-awareness; Conscious OS (7 August 2015) and Sensory Perceptions (23 February 2015) treat conscious awareness as intermittent, layered over continuous subconscious activity; Time Alert (2 March 2016) argues consciousness is constitutively temporal. The same register extends to artificial minds: Artificial Humanness (2 March 2016) and More on Chess (1 March 2016) tie machine consciousness to processing power and mortality-awareness rather than to any categorical exceptionalism for biological minds.
8.4 Constructed reality, simulation, and the limits of perception
A fourth thread treats perceived reality as constructed rather than directly given. The matrix (23 July 2013) argues that brains construct subjective realities the author likens to virtual reality; Simulation (26 February 2025) extends this to a speculative scenario of consciousness transfer into a computer-simulated substrate; Trailer Park (23 January 2015) frames self-awareness as an evolutionary layer imposed on animal sentience, producing internal conflict as a structural feature of mind. This connects the archive’s naturalism about consciousness to a broader constructivism about perception, consistent with the simulation argument in analytic philosophy (Bostrom, 2003).
8.5 Meaning after nihilism
Boggle (24 January 2025) compares existentialist, nihilist, absurdist, and religious responses to the absence of inherent meaning, recalling the absurdist position associated with Camus (1942), that meaning must be enacted rather than discovered. Ennui too (21 December 2013) makes a related point personally, arguing that if a person’s purpose has been self-understanding, a new purpose must be consciously located once that project is complete, on pain of ennui. Read against 8.2 and 8.3, the corpus’s metaphysics is consistently anti-foundationalist: nothingness is a limit case taken seriously, consciousness is constructed and evolved rather than fundamental, and meaning is actively sustained rather than a fixed property of the universe.
8.6 Synthesis
These five threads describe a coherent, if informally developed, position that recurs independently of the categorical and tonal shifts documented in section 5: the archive borrows physical formalism to think about mind, relationship, and law; treats absence and vanishing as substantive; insists on falsifiable, naturalistic accounts of consciousness even while speculating about it; extends that naturalism into a constructivist account of perceived reality; and treats meaning as something actively sustained against an indifferent backdrop. It is not presented anywhere in the corpus as a formal system, and the posts composing it range from analytical to satirical to personal; the coherence identified here is a pattern visible across the archive rather than a claim made by any single post.
9. Does a Coherent Life Philosophy Emerge?
The modelling primitives in section 7 describe how the archive reasons; the metaphysical commentary in section 8 describes what it assumes about mind and reality. Neither directly answers a more personal question the author has posed of the corpus: whether more than thirteen years of writing amount to a coherent life philosophy, one that functions in daily life and might also be of use to others. This section reads the corpus for that question specifically, again illustrated with representative posts rather than aggregate counts.
9.1 A recurring practical core
Five practical commitments recur across the archive closely enough, and over a long enough span, to function as load-bearing rather than incidental. The first is expectation management as the mechanism of contentment, rather than contentment sought directly: Contentment (21 April 2013, 19 May 2013), Lottery of life (16 April 2013) and Sans entitlement (4 October 2013) all argue that lowering expectations increases the ratio of received to expected outcomes, a relationship later made explicit as a contentment ratio applied to commuting and lifestyle choices (Alpha Delta Epsilon, 4 April 2017) and to relationships (Long Haired Lover, 9 April 2017). The second is a preference for honesty over self-protective concealment, presented as adopted rather than innate: Honesty and Honesty II (13 April 2013) treat total honesty as socially costly, Trust and Faith (23 May 2015) frames honesty as a moral practice that prevents escalation of lies, and Diff (26 June 2018) records the shift itself, the author noting a move from lying to avoid consequences toward telling the truth or a version of it. The third is treating failure and contradiction as information rather than as a threat to identity, expressed in How to fail properly (25 September 2019) and revisited six years later in Failure, expanded (3 June 2025), a recurrence that suggests the theme was worth returning to rather than settled once. The fourth is generosity and non-retaliation adopted as a considered strategy rather than a passive default: TT (13 February 2019) explicitly frames choosing generosity over revenge as a way to break a cycle of workplace vindictiveness rather than as an emotional reflex. The fifth is acceptance of mortality and impermanence applied practically rather than left abstract: Fear (12 June 2013) describes teaching a nine-year-old to acknowledge fear of mortality rather than avoid it, and Ageing (17 October 2025) returns to the same acceptance twelve years later in relation to the author’s own ageing and the deliberate relinquishing of control.
9.2 A self-aware audit, not an uncritical one
The corpus does not only state this philosophy; it examines it. Machiavellian Philosophy (25 August 2015) explicitly compares Epicurean and Machiavellian influences on the author’s own life philosophy, evidence that the position has, at least once, been named and inspected directly rather than only practised implicitly. More important for the present question is Parable Bias (23 May 2025), which names a discrepancy between professed wisdom and self-destructive behaviour. This post matters because it shows the archive already contains its own audit of whether the stated philosophy is actually followed, rather than presenting only a catalogue of the philosophy’s content. Read alongside section 9.1, the corpus does not claim a philosophy perfectly lived; it presents one repeatedly stated, occasionally re-examined, and at least once explicitly flagged by its own author as imperfectly practised.
9.3 Transmission to others
The archive shows sustained, explicit attempts to transmit these commitments to a specific other person, not only to a general reader. Parenting posts addressed to or about the author’s daughter recur across the full archive, from For Lola (2 October 2013) and Note to Lola (17 March 2015) through Parenting: teaching to learn from choices rather than regret (6 June 2016) and Ocean Shores (3 January 2017) to Lola, for the record (8 December 2018). A smaller set of posts addresses a general reader directly in the register of advice, including Gen Y Advice (8 September 2015) and Pearls of wisdom #1 (18 October 2018). The intent to transmit is well evidenced in the text; whether the transmission succeeded, for a daughter or for any reader, is not something a text corpus can establish, since the archive records what was offered rather than what was received.
9.4 What the pattern can and cannot show
The consistency of a stated position across more than thirteen years, restated in new language across every phase identified in section 6 including the quiet years of 2017 to 2022, is evidence that the position is durable enough to be worth returning to. It is not, by itself, evidence that the position was, or is, evenly practised, or that it delivers the wellbeing it promises; Parable Bias is a reminder written by the author himself that stating a philosophy and living it consistently are not the same thing. Whether the philosophy serves the author well in daily life is a question only he is positioned to answer. What the corpus can say is narrower and, on its own terms, still notable: the same five commitments, expectation management, honesty, treating failure as information, generosity as strategy, and acceptance of mortality, recur across more than thirteen years and multiple genres, from aphorism to parenting note to formal comparison, and the corpus includes its own record of questioning whether they are kept.
10. Situating the Self: Other Models of Reasoning and Identity
Sections 7 and 9 describe recurring patterns, modelling primitives and a practical life philosophy, largely in the archive’s own terms. Several established traditions in psychology and philosophy offer more precise vocabularies for the same patterns, and situating the corpus against them strengthens the claim that what has been observed is a recognisable kind of thing rather than an artefact of this particular description.
10.1 Personal construct theory
Kelly’s personal construct theory (1955) proposes that a person functions as an intuitive scientist, forming constructs about the world, testing them against experience, and revising or discarding them when prediction fails. This is close to a direct match for the reasoning cycle set out in section 2: Kelly’s constructs are the archive’s assumptions, his process of validation and invalidation is the archive’s limiting-case testing and contradiction, and his emphasis on constructs as revisable rather than fixed is exactly what the assumption ledger in section 2.1 is built to preserve. Read through Kelly, the corpus is not merely analogous to scientific reasoning; on his account, that is what ordinary personality formation already is, and the archive is an unusually complete external record of a process every person carries out internally and, for the most part, invisibly.
10.2 Narrative identity and the idem or ipse distinction
McAdams’ narrative identity theory (1993) holds that a person’s sense of self is constituted by an evolving personal story rather than by a fixed set of traits, integrating disparate experiences into a life narrative that itself changes over time. Ricoeur’s distinction (1992) between idem-identity, sameness of measurable characteristics, and ipse-identity, selfhood constituted by narrative continuity, sharpens the point made informally in section 6.4. The corpus’s idem-identity, its topics, categories, and named entities, changes substantially between 2013 and 2026, with Personal share falling well back and an increasingly AI-inflected mix emerging alongside a persistently dominant Society category and a persistently prominent Australia (Table 3, Table 5). Its ipse-identity, the reasoning architecture described in section 7 and the practical commitments described in section 9, persists through that change. Ricoeur’s distinction gives this persistence a name: the archive demonstrates ipse-continuity alongside substantial, though partial, idem-discontinuity, which is a stronger and more specific claim than simply noting that the author’s reasoning style seems stable.
10.3 Technologies of the self and philosophy as a way of life
Foucault’s technologies of the self (1988) and Hadot’s account of ancient philosophy as a way of life (1995) describe a much older tradition of exactly this kind of practice: Seneca’s letters, Marcus Aurelius’s private notebook that became the Meditations, and the Stoic and Epicurean habit of daily written self-examination as the mechanism by which an ethical stance is actually formed and maintained, not merely recorded after the fact. This tradition speaks directly to the question posed in section 9, whether a life philosophy has been developed and lived, because it treats the writing itself as the technology by which a self is worked on, rather than as a passive report of a self formed elsewhere. Machiavellian Philosophy (25 August 2015), which explicitly compares Epicurean and Machiavellian influences on the author’s own outlook, situates the corpus inside this tradition by name; Parable Bias (23 May 2025), which catches a gap between professed wisdom and behaviour, is exactly the kind of self-correction this tradition expects such a practice to produce over time, evidence that the technology is active rather than decorative.
10.4 Reflective practice
Schön’s account of reflective practice (1983) distinguishes knowing-in-action, the tacit competence a practitioner exercises without articulating it, from reflection-on-action, the deliberate, often written, examination of that competence after or during the fact. Schön’s professionals develop a repertoire of cases and framing moves that they carry across superficially unrelated problems, which is a close match for the finding in section 6.4 that a post on patent valuation and a post on quantum error correction are generated by the same underlying procedure. On this reading, the modelling primitives in section 7 are the archive’s repertoire in Schön’s sense, and each new domain the archive takes up, business, AI, quantum computing, parenting, is less a new interest than a new case to which an existing reflective practice is applied.
10.5 Cybernetics: the archive, and this paper, as a feedback loop
A fifth model fits the corpus more literally than metaphorically: cybernetics, the study of circular, self-correcting causal processes (Wiener, 1948). Wiener’s basic unit, a system that acts, observes the consequence, compares it against a goal, and adjusts, restates the reasoning cycle of section 2 in engineering terms: observation and model are the action, limiting-case testing is the comparison, and contradiction-driven revision is the corrective feedback. Ashby’s requisite variety (1956), the principle that a regulator must command at least as much variety as the disturbances it controls, offers a reading of why the archive’s modelling domain keeps expanding into politics, patent law, quantum computing and artificial intelligence: each new domain supplies variety against which the reasoning repertoire of section 7 can be tested.
Producing this paper is a live instance of the same structure, now running between the author and a large language model rather than largely inside one person: assumptions proposed, tested, revised, and re-archived across successive turns, with the model an active component of the loop rather than only the annotation instrument of section 11.2. This is close to Bateson’s sense (1972) of mind as a pattern of circular relations rather than a property of one brain, and to von Foerster’s second-order cybernetics (1974), where the observer is part of the system observed, exactly the author’s position while directing revisions to a paper about his own reasoning; it also connects to Engelbart’s programme for augmenting human intellect (1962), which frames this paper’s working method as an application of the same aim, extending reasoning rather than only recording it. This deserves a caution as much as an observation: a system studying itself, with a component of that system helping to write the study, is exactly the situation cybernetics flags as prone to blind spots the observer cannot see from inside the loop, a risk examined directly in the author’s own prior work on semantic drift across recursive LLM generation (Maxwell, 2025d) and on meta-cognitive framing of the prompting process itself (Maxwell, 2025c); the convergence in section 10.6, and this paper’s own claims, should be read with that limit in mind rather than as a vantage point exempt from it. On this reading the paper is itself a further entry in the assumption ledger of section 2.1, not a report handed back to the archive from outside it, a point developed further in the conclusion.
10.6 What these models add
None of these five traditions was designed with this archive, or with language model annotation, in mind, which is part of why their convergence is informative rather than merely convenient. A cognitive-personality theory (Kelly), a hermeneutic theory of selfhood (Ricoeur, alongside McAdams), a philosophical and historical tradition of ethical self-formation through writing (Foucault, Hadot), a theory of professional cognition (Schön), and a general theory of self-correcting feedback systems (Wiener, Ashby, Bateson, von Foerster) each independently describes or accommodates the central pattern reported in sections 6 through 9: stable underlying structure, whether called constructs, ipse-identity, a technology of the self, a reflective repertoire, or a regulated feedback loop, persisting beneath changing surface content. This convergence does not establish that the archive reveals something general about human reasoning, a claim section 12 explicitly declines to make, but it does support a narrower claim: the pattern identified in this single corpus is not sui generis. It is a specific, unusually extensive instance of phenomena that psychology, philosophy, and systems theory have independently described in other people and other systems, by other methods, for a long time.
11. Discussion
11.1 External memory and cognitive persistence
Human memory is adaptive but not an objective historical record: memories compress, intermediate reasoning is discarded, and failed explanations disappear, leaving narratives that appear more coherent than the reasoning that actually produced them. An external reasoning archive behaves differently, preserving observations before their significance is understood and models that later prove wrong, so that it retains not only knowledge but the historical development of knowledge, a form of epistemic rather than autobiographical memory whose value lies in the pathways it keeps rather than the conclusions alone.
11.2 Large language models as a semantic excavation tool
The methodology also illustrates an application of large language models distinct from text generation: here the model functions as a semantic coding instrument, converting thousands of individual posts into structured, comparable observations from which patterns invisible within any single entry become visible only after aggregation. The model does not provide the paper’s higher-level interpretation of the corpus; it produces structured annotations, themselves a form of interpretation at the level of individual posts, from which the corpus-level interpretation in sections 6 to 8 is developed, at substantially lower cost than manual coding at this scale.
11.3 Beyond Offshore Westerly
The archive analysed here is a single case, but the significance of the paper, if any, does not lie in Offshore Westerly itself. The same method could be applied to any comparably complete personal record extending over years or decades: laboratory notebooks, engineering journals, research blogs, developer diaries, or design logs, none of which have until recently been costly to investigate quantitatively at full-corpus scale, since manual semantic coding of an entire long-running archive demanded prohibitive amounts of time. Schema-constrained language model annotation changes that calculus, making it practical to convert any such archive into a structured longitudinal dataset. The broader claim advanced here is methodological, and it is the larger contribution: long-running external reasoning systems, not blogs or diaries as conventionally understood, constitute a distinct and measurable class of cognitive artefact, and the method demonstrated on one archive is available to anyone with a long enough record of their own reasoning to apply it to. Sections 5 and 7 establish that methodological contribution on quantitative and semi-quantitative grounds alone. Sections 8 through 10 may also be read as a distinct interpretive study built on the same corpus, rather than as a continuation of the same argument.
11.4 A practical application: structured self-reflection tools
The method demonstrated here, retrospectively, on an archive written for other purposes, could in principle be built prospectively, as a tool designed from the outset to generate an assumption ledger. A structured daily or weekly practice, in which a person answers a small set of consistent prompts, what was observed, what was assumed, what was predicted, what actually happened, would produce exactly the kind of longitudinal, intermediate-state-preserving record analysed in this paper, and the same schema-constrained annotation approach used in section 4.3 could be applied to identify recurring patterns back to the person who wrote it, in roughly the way sections 6 through 9 identifies patterns back to the reader here. This is not a new therapeutic idea in its essentials; structured self-monitoring and thought-record techniques of this kind are already established components of cognitive behavioural therapy, and what a language model plausibly adds is a lower-friction way to sustain the practice and to aggregate patterns across a longer history than a person or a single clinician session can easily hold in view at once.
This application should be described carefully rather than framed as a substitute for professional care. A language model has no duty of care, no clinical training in risk assessment, and no reliable, validated mechanism for recognising acute crisis, such as suicidality, self-harm, or psychosis, from journaling text alone; any tool built on this method would need an explicit, conservative, human-in-the-loop escalation pathway for exactly the content it will eventually encounter, and should be positioned as a self-reflection and psychoeducational aid that complements rather than replaces a clinician. Structured daily self-observation is also not uniformly beneficial: for some presentations, particularly rumination and certain anxiety and obsessive patterns, prompted introspection can entrench distress rather than relieve it, which is a design problem to be actively guarded against rather than an incidental risk. The approach would additionally involve sustained collection of detailed personal psychological data, raising privacy, consent, and data-security obligations well beyond those of the present paper, and a deployed version making any therapeutic claim would likely fall within software-as-a-medical-device or equivalent regulatory frameworks in most jurisdictions, a governance question that is separate from, and prior to, the technical feasibility this paper demonstrates. What the paper’s method actually licenses is narrower and more defensible: that schema-constrained language model annotation can convert a structured, longitudinal self-report record into an empirically legible pattern of reasoning and concern over time. Whether, and under what safeguards, that capability should be packaged as a self-help product is a design and governance question outside the scope of this paper.
12. Limitations
Several limitations bound the interpretation offered here. Classification was performed by a single automated pipeline rather than multiple independent human coders, and no inter-coder reliability statistic such as Cohen’s kappa or Krippendorff’s alpha can therefore be reported; the results should be read as a systematic single-coder classification rather than a validated one. Section 4.6 reports a supplementary annotation-consistency check using a second language model in place of a human coder, run against the full retrieved text of each sampled post, which found 78 percent category agreement and 42 percent tone agreement on a random sample of fifty posts; an earlier version of this check that reused subject and summary fields generated by the original pipeline had reported 96 percent and 94 percent respectively, and the gap between the two versions confirms that the earlier figures were substantially inflated by information leakage. Even the corrected check compares two automated coders rather than a coder against an independent human reading, and is therefore not a substitute for human validation against the source text; the marked weakness of tone agreement in particular suggests that tone labels should be treated as considerably less reliable than category labels throughout this paper. A human manual review of a random sample, for example 100 posts, reporting percentage agreement against the original labels together with examples of the most common disagreements, remains the most important item of future validation work and would materially strengthen the results reported here. A meaningful share of the corpus, on the order of several hundred posts based on the frequency of empty and title-only keyword tags, contains no substantive body content; these posts remain in the volume counts in Table 1 and inflate raw totals relative to a corpus of substantive content only. Category and tone labels are not mutually exclusive at the post level, since posts carry secondary categories in addition to a primary category, not reflected in the totals reported here.
The entity and keyword frequencies in Tables 5 and 6 are model-assigned labels rather than normalised, deduplicated concepts: United States and US, Australia and Australians, and GPT and ChatGPT each appear as separate entries where a normalised count would merge some of them, so these tables should be read as counts of posts assigned a given label by the model rather than clean, deduplicated entity frequencies. The exact model snapshot, prompt version, code version, and generation temperature used for classification were not separately preserved as a fixed, dated record at the time of annotation, beyond the configured model identifier reported in section 4.3; this limits exact reproducibility, and reproducing this analysis would require either access to a stable, dated model snapshot from the provider or acceptance that results may vary slightly with model version.
The reasoning-system interpretation carries its own limitations. The archive represents one system maintained by one individual over more than thirteen years, so the paper does not attempt statistical generalisation; its contribution, as with single-case studies elsewhere in cognitive science, is methodological rather than an estimate of population parameters. The modelling primitives in section 7 were identified through repeated qualitative examination of the annotated corpus together with long familiarity with the archive, not generated algorithmically, and future work could attempt to recover comparable structures directly from argument structure rather than semantic content alone. Publication is also only observable behaviour; reasoning that was never externalised, or that was recorded elsewhere, is invisible to this analysis, a limitation that applies to any external reasoning record rather than to this archive specifically. Finally, the metaphysical reading in section 8 is interpretive, based on a keyword-guided rather than exhaustive review of the corpus, and should be read as one plausible synthesis among others the archive could support.
13. Conclusion
Human reasoning is normally invisible because memory preserves conclusions while discarding most of the intermediate models that produced them. This paper has treated Offshore Westerly as a case in which those intermediate states were retained, allowing the evolution of reasoning itself, rather than only its conclusions, to become an empirical object. The 5,647 posts of the archive show publication activity moving through three phases, a prolific founding period, a prolonged decline, and a recent revival, with thematic composition shifting from a Personal and Society mix toward a Society-led, increasingly AI-inflected mix, while Observational and Critical tones and a small number of recurring entities, chiefly Australia and the author’s immediate personal circle, persist throughout.
Taken alone, these findings describe the evolution of a long-running blog. The paper’s principal argument is that this description is incomplete. Read as an external reasoning system, the observed movement from Personal toward Society and Artificial Intelligence does not necessarily indicate changing beliefs so much as changing domains within which a stable reasoning process, built from information, explicit assumptions, simplification, limiting cases, contradiction, incentives, measurement and falsifiability, was exercised. New technologies and public events supplied new modelling environments; the analytical architecture applied to them changed comparatively little, and a qualitative reading of the same corpus identifies a further, comparably stable metaphysical stance beneath the reasoning architecture itself, treating physical formalism as a tool for thinking about mind and relationship, nothingness as a substantive concern, consciousness as naturalistically evolved, and meaning as something to be actively sustained.
The methodological contribution follows from this reading. Schema-constrained large language model annotation converts an extensive personal reasoning archive into a structured longitudinal dataset without prohibitively expensive manual coding, while the interpretation of that dataset remains a human task. The publication platform happened to be WordPress. The object of study was the reasoning system the blog made observable, and further work, a manual reliability check, a second independent coder, and application of the same method to comparable archives, would help establish how much of this pattern is particular to one archive and how much reflects a more general feature of sustained personal reasoning conducted in public.
As section 10.5 argues, this paper is itself a further entry in the same assumption ledger rather than a report delivered to the archive from outside it. Whether the practical philosophy examined in section 9 serves the author well cannot be settled by the paper that asks the question; what can be said is that continuing to ask it, in public and in a form that can later be checked against itself, is the method the corpus has used throughout.
References
Ashby, W. R. (1956). An Introduction to Cybernetics. Chapman and Hall.
Bateson, G. (1972). Steps to an Ecology of Mind. Chandler.
Baumann, J., Röttger, P., Urman, A., Wendsjö, A., Plaza-del-Arco, F. M., Gruber, J. B. and Hovy, D. (2025). Large language model hacking: Quantifying the hidden risks of using LLMs for text annotation. arXiv:2509.08825. https://doi.org/10.48550/arXiv.2509.08825
Bostrom, N. (2003). Are we living in a computer simulation? The Philosophical Quarterly, 53(211), 243 to 255. https://doi.org/10.1111/1467-9213.00309
Calderon, N., Reichart, R. and Dror, R. (2025). The alternative annotator test for LLM-as-a-judge: How to statistically justify replacing human annotators with LLMs. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 16051 to 16081. https://doi.org/10.18653/v1/2025.acl-long.782
Camus, A. (1942). Le Mythe de Sisyphe. Gallimard.
Clark, A. and Chalmers, D. (1998). The extended mind. Analysis, 58(1), 7 to 19. https://doi.org/10.1093/analys/58.1.7
Engelbart, D. C. (1962). Augmenting Human Intellect: A Conceptual Framework. Stanford Research Institute.
Foucault, M. (1988). Technologies of the self. In L. H. Martin, H. Gutman and P. H. Hutton (Eds.), Technologies of the Self: A Seminar with Michel Foucault (pp. 16 to 49). University of Massachusetts Press.
Gilardi, F., Alizadeh, M. and Kubli, M. (2023). ChatGPT outperforms crowd-workers for text-annotation tasks. Proceedings of the National Academy of Sciences, 120(30), e2305016120. https://doi.org/10.1073/pnas.2305016120
Gu, F., Li, Z., Colon, C. R., Evans, B., Mondal, I. and Boyd-Graber, J. L. (2025). Large language models are effective human annotation assistants, but not good independent annotators. arXiv:2503.06778. https://doi.org/10.48550/arXiv.2503.06778
Grimmer, J. and Stewart, B. M. (2013). Text as data: The promise and pitfalls of automatic content analysis methods for political texts. Political Analysis, 21(3), 267 to 297. https://doi.org/10.1093/pan/mps028
Grimmer, J., Roberts, M. E. and Stewart, B. M. (2022). Text as Data: A New Framework for Machine Learning and the Social Sciences. Princeton University Press.
Hadot, P. (1995). Philosophy as a Way of Life: Spiritual Exercises from Socrates to Foucault. Blackwell.
Holsti, O. R. (1969). Content Analysis for the Social Sciences and Humanities. Addison-Wesley.
Kaye, B. (2007). Blog use motivations: An exploratory study. In M. Tremayne (Ed.), Blogging, Citizenship, and the Future of Media (pp. 127 to 148). Routledge.
Kelly, G. A. (1955). The Psychology of Personal Constructs. Norton.
Krippendorff, K. (2018). Content Analysis: An Introduction to Its Methodology (4th ed.). Sage Publications.
Maxwell, I. A. (2025a). Controlling semantic meaning through vocabulary compression using Longman Defining Vocabulary constraint to measure and improve large language model output quality. Zenodo. https://doi.org/10.5281/zenodo.15844892
Maxwell, I. A. (2025b). Evaluating the impact of LDV-constrained prompting on accuracy, precision, and clarity in LLM outputs. Zenodo. https://doi.org/10.5281/zenodo.15844923
Maxwell, I. A. (2025c). Meta-cognitive prompting: A comparative framework for prompt engineering in large language models. ResearchGate. https://doi.org/10.13140/RG.2.2.22405.46562
Maxwell, I. A. (2025d). The half-life of truth: Semantic drift vs factual degradation in recursive large language model generation. ResearchGate. https://doi.org/10.13140/RG.2.2.16533.44000
McAdams, D. P. (1993). The Stories We Live By: Personal Myths and the Making of the Self. Morrow.
Popper, K. (1959). The Logic of Scientific Discovery. Hutchinson.
Ricoeur, P. (1992). Oneself as Another. University of Chicago Press.
Schön, D. A. (1983). The Reflective Practitioner: How Professionals Think in Action. Basic Books.
von Foerster, H. (1974). Cybernetics of cybernetics. University of Illinois Biological Computer Laboratory.
Wiener, N. (1948). Cybernetics: Or Control and Communication in the Animal and the Machine. MIT Press.
Ziems, C., Held, W., Shaikh, O., Chen, J., Zhang, Z. and Yang, D. (2024). Can large language models transform computational social science? Computational Linguistics, 50(1), 237 to 291. https://doi.org/10.1162/coli_a_00502